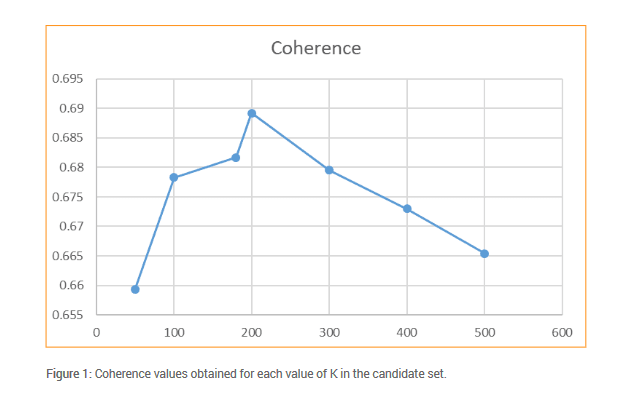
The parameters α and β are computed at the corpus level. In addition to these parameters, when implementing an LDA model, we must carefully choose the optimal number of topics (K) that the model can identify. This step is crucial as it significantly impacts the interpretability of the topics generated by the model. To determine the optimal number of topics, we conduct a search among a set of candidate values for K (50, 100, 180, 200, 300, 400, and 500).
In our implementation, we select the number of topics that maximises the coherence among the topics. Coherence, a measure of semantic consistency, plays a key role in this selection process. Therefore, a higher probability of top-ranked words co-occurring within a document reflects a better classification effect of the model.
On the following page, Figure 1 illustrates the coherence scores obtained for each value of K in the set of candidate values. The maximum coherence is achieved when the model identifies 200 topics.